home..
자연어 생성 모델(디코더)
개요
자연어 생성은 단어들의 시퀀스를 출력으로 냅니다.
일반적으로 생성 모델은 각각의 디코딩 타임 스텝에서 전체 단어 사전에 대한 확률 분포를 예측합니다.
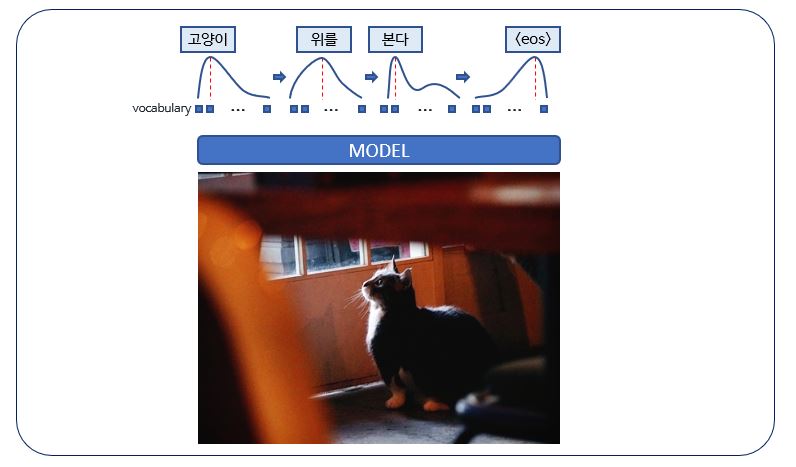
예측된 확률 분포에 따라 가능한 모든 출력 시퀀스 조합을 탐색해야하는데
사실상 모든 조합을 탐색하기는 불가능하므로 휴리스틱한 방법을 사용합니다.
디코딩 전략
Greedy Search Decoder
가장 직관적인 방법으로 각각의 확률 분포에서 가장 값이 높은 토큰을 선택하는 방법입니다.
간단하면서도 빠르지만 몇몇 경우에서는 잘못된 결과를 초래할 수 있습니다.
Beam Search Decoder
각 스텝에서 탐색의 영역을 k개의 가장 가능도가 높은 토큰들로 유지하며 다음 단계를 탐색합니다.
이 때 k는 hyper-parameter이므로 적절한 k를 설정하는 것이 중요하며 보통 기계 번역 작업에서는 5~10으로 설정합니다.
동어반복 문제가 심한 편이기 때문에 이를 해결하기위해 n-gram 패널티 전략을 사용하기도 합니다.
Sampling
모델이 생각하는 다음에 올 토큰에 대한 확률분포에 따라 단어를 샘플링하는 방식으로 디코딩하는 전략입니다.
Top-k Sampling
가장 확률이 높은 k개의 ‘다음 단어들’을 필터링하고, 확률 질량을 해당 k개의 ‘다음 단어들’에 대해 재분배하는 전략입니다.
- GPT-2에서 선택한 전략으로, 스토리 생성에서 큰 효과를 보였습니다.
Top-p Sampling
누적 확률이 확률 p에 다다르는 최소한의 단어 집합으로부터 샘플링하는 전략입니다.
현재 디코딩 전략의 한계
- 여전히 동어 반복 문제가 있습니다.