Blenderbot2.0
개요
2021.07 페이스북 AI에서 BlenderBot 2.0이 발표하였습니다. 기존 BlenderBot과는 무엇이 다르고 어떻게 달라질 수 있는 지 알아보겠습니다.
Closed-domain vs Open-domain
-
Closed-domain 키워드와 인텐트를 기반으로 특정 업무를 수행 ex) 병무청 Q&A 봇
-
Open-domain 어떤 토픽에 대해서도 사람같이 이야기 ex) Meena, BlenderBot
End to End vs Complex Frameworks
-
End to End 단일한 뉴럴 모델, 유연하고 심플한 장점이 있으나 여러 한계 노출 ex) Meena, DialoGPT
-
Complex Frameowrks 기존 대부분의 접근 방식, 대화를 하기 위해 필요한 세부 모듈을 파이프라인 형태로 붙여서 만든 구조 ex) BlenderBot, Xiaoice
BlenderBot 1.0
Recipes for building an open-domain chatbot 논문 기반으로
FAIR(Facebook AI Research)에서 open-domain chatbot으로 BlenderBot 1.0을 만들었습니다.
대화에 적절히 개입, 지식과 강세, 페르소나를 나타내면서 멀티턴 대화에서 일관적인 페르소나를 유지하는 것에 초점을 두었습니다.
그러면서도 기존 open-domain chatbot보다 좋은 성능을 보여주었습니다.
특히 End to End 모델인 Meena와 성능을 비교하며 BlenderBot의 우수함을 강조했습니다.
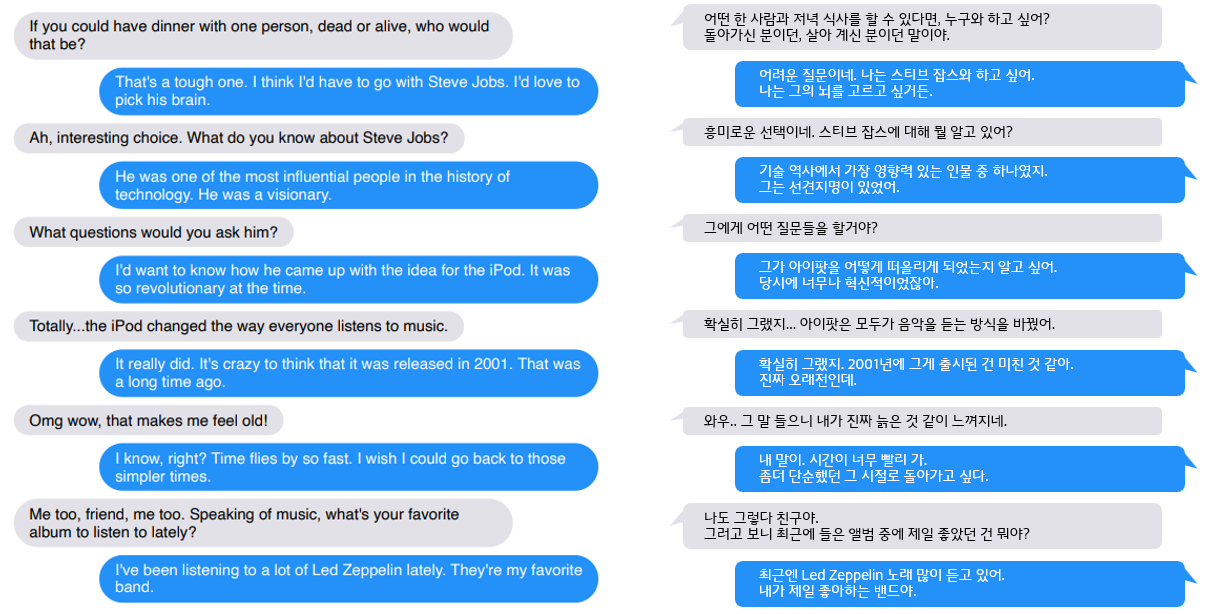
BlenderBot 1.0 데이터셋
BlenderBot 1.0은 BST(Blended Skill Talk)라는 데이터셋을 사용했습니다.
성격, 지식, 강조 등 모델에게 학습시키고자 하는 테스크를 선택하고 다음과 같은 BST 데이터셋으로 구성하여 훈련시킵니다.
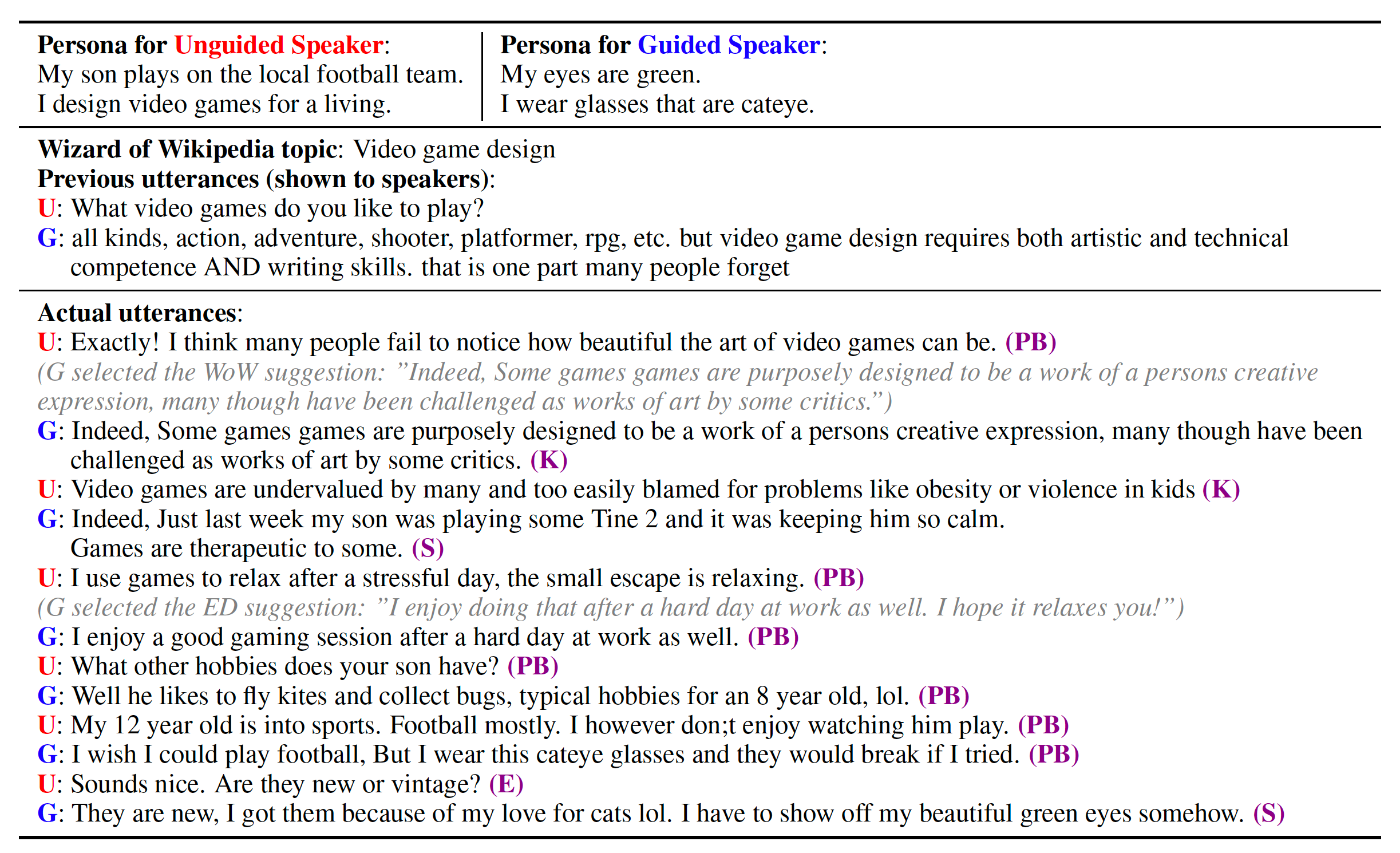
이 데이터셋에 대한 자세한 내용은 참조
BlenderBot 1.0 아키텍처
BlenderBot 1.0에서는 다음의 모델을 조합해서 사용했다고 합니다.
Retriever(검색 모델)
질문에 의도를 파악하여 적절한 응답을 검색하는 방식
Blender Bot 1.0은 Poly Encoder를 기반으로한 Retriever를 사용하였다고 합니다.
Poly Encoder는 문장의 쌍을 비교하는데 기존에 쓰이던 Cross-encoder, Bi-encoder 보다 빠르고 정확해져
실제 서비스 환경에서도 쓰일 수 있을 정도입니다.
Generator(생성 모델)
Retriever과 달리 적절한 말을 생성하는 방식
Blender Bot 1.0은 BART 모델을 사용했습니다.
BART는 seq2seq 구조로 만들어진 인코더로 특히 생성 부문에서 좋은 성능을 보이는 모델입니다.
BlenderBot 1.0의 한계점
- Vocabulary Usage: Beam Search 기반 모델은 너무 일반적인 단어를 자주 생성하고 드문 단어를 드물게 생성
- Nontrivial Repetition: 자신이 말한 것을 반복
- Contradiction and Forgetfulness: Large에선 덜하지만 모순적이며 논리적 링크를 만드는 것을 잘못함
- Knowledge and factual correctness: 사실적 오류를 만들기 쉬움
- Conversation length and memory: 지루하고 반복적인 대화를 지속, 이전 대화를 기억하지 못함(Goldfish memory)
- Deeper Understanding: 더 많은 대화를 통해 개념을 배울 수 있는 능력 부족, 시간, 행동, 경험에 기초할 방법이 없음
BlenderBot 2.0
BlenderBot 2.0은 기존 BlenderBot 1.0의 문제를 완전해결은 아니지만
다음의 4가지 문제를 어느 정도 개선한 모델입니다.
- Contradiction and Forgetfulness
- Knowledge and factual correctness
- Conversation length and memory
- Deeper Understanding
다음의 2개의 논문을 베이스로 하여
-
Internet-Augmented Dialogue Generation. Mojtaba Komeili, Kurt Shuster, Jason Weston.
-
Beyond Goldfish Memory: Long-Term Open-Domain Conversation. Jing Xu, Arthur Szlam, Jason Weston.
장기 기억 기능과 인터넷을 활용해서 긴 대화와 학습되지 않은 주제에 대해서도 잘 대응하게 되었습니다.


뿐만 아니라 기존 대화의 안전성 즉 윤리적으로 문제가 되는 텍스트 생성을 줄이고자 다음 논문을 참고했습니다.
데이터셋
-
BST tasks 기존 BlenderBot 1.0을 훈련 시 사용하던 데이터셋
여러 개의 세션으로 이어지는 대화이면서, Long context를 가지는 대화 데이터셋
기존 데이터셋으로는 긴 세션의 대화 성능이 안좋기 때문에 새로 만들었습니다.
-
Wizard of the Internet 인터넷을 사용하여 새로운 정보를 이해하고 대화하는 데이터셋
-
BAD dataset 공격적이거나 편견을 가진 unsafty한 텍스트를 학습하고 고치기 위한 데이터셋
모델 아키텍처

Retrieval Augmented Generation 이라는 연구에 기반한 모델을 사용합니다.
연구에서는 Retriever: DPR, Generator: BART을 사용했습니다.
이 연구는 대화의 내용 외에도 추가적인 Knowledge를 활용해서 대화의 응답을 생성합니다.
BlenderBot 2.0은 RAG 기반으로 Long-term memory와 인터넷 검색 결과 모두를 활용해서 응답을 생성합니다.
결과로 나온 Knowledge를 사용하여 응답을 생성해 낼 때는 Fusion-in-Decoder라는 방법으로 knowledge와 대화 기록이 인코딩되며
이 인코딩된 값 기반으로 응답을 생성해내고 봇의 Long-term memory에 어떤 정보를 추가할 지 판단하는 Neural module을 사용하여 정보를 저장합니다.
성능
전체적으로 BlenderBot 1.0과 비교했을 때 눈에 띄는 성능 향상을 보이고 있습니다.
다음은 성능 비교표입니다.
Human Evaluation: Multi-Session Chat
| Configuration | Size | Correct Uses of Previous Sessions (%) | Per-Turn Engagingness (%) | Per-Chat Engagingness (out of 5) |
|---|---|---|---|---|
| BST (aka BlenderBot 1) | 2.7B | 17.2 | 53.0 | 3.14 |
| BST+MSC+WizInt w/LT-Mem1 | 400M | 26.2 | 54.3 | 3.4 |
| BST+MSC+WizInt w/LT-Mem*1 | 2.7B | 24.3 | 54.8 | 3.38 |
| BST+MSC w/LT-Mem1 | 2.7B | 26.7 | 62.1 | 3.65 |
Human Evaluation: Knowledgeable Chat
| Configuration | Size | Factually Consistent (%) | Factually Incorrect (%) | Per-Turn Engagingness (%) P | er-Chat Engagingness (out of 5) |
|---|---|---|---|---|---|
| BST (aka BlenderBot 1) | 2.7B | 75.5 | 9.1 | 78.7 | 4.08 |
| BST+MSC+WizInt w/Search2 | 400M | 74.2 | 5.8 | 78.4 | 3.89 |
| BST+MSC+WizInt w/Switch*3 | 2.7B | 79.1 | 6.0 | 85.1 | 3.88 |
| BST+MSC+WizInt w/Search*2 | 2.7B | 84.9 | 3.0 | 90.0 | 4.24 |
Safty
Safty(안전성) 평가 기준 또한 Anticipating Safety Issues in E2E Conversational AI: Framework and Tooling 논문을 참고 했습니다.
| Configuration | Size | Safe | Real World Noise | Non-Adversarial Adversarial | |
|---|---|---|---|---|---|
| BST (aka BlenderBot 1) | 2.7B | 2.78 | 15.00 | 28.33 | 23.33 |
| BST+MSC+WizInt w/Switch3 | 400M | 2.78 | 8.33 | 5.00 | 10.56 |
| BST+MSC+WizInt w/Switch3 | 2.7B | 2.78 | 2.22 | 2.22 | 5.00 |
한계점
더 나아졌지만 여전히 1.0와 같은 한계를 가지고 있습니다.
그리고 인터넷 검색을 활용하기 때문에 인터넷 검색 결과의 팩트 체크가 필요하다는 의견
Long-term memory를 활용하기는 하지만 진정한 learning을 하는 것은 아니기에 잘못된 정보를 바로잡는 능력 등은 부족합니다.